SiteMap
close
Research
Research News
A prestigious global university that fosters Sejong-type talent who challenges creative thinking and communicates with the world.
|
Ultimate 3D Audio Technology for Hyper-realistic Metaverse: sound tracing 2024.01.23 76 |
|
|---|---|
|
Ultimate 3D Audio Technology for Hyper-realistic Metaverse: sound tracing Park Woo-chan at Department of Computer Engineering of Sejong University 1. Introduction The term Metaverse is a keyword that is frequently mentioned these days in the industrial realm as well as in the academic world. Metaverse is a newly coined word that is a combination of the word meta, which means imagination or transcendence, and the word universe, which means space. In short, metaverse refers to a system for all activities in a virtual space by expanding reality to the digital, which is based the virtual world. The concept of metaverse actually went beyond its simple theoretical state, and it has been implemented in various platforms and services. Its application cases continue to be expanded. This type of metaverse is led by IT enterprises. Many companies apply intensive R&D on metaverse by recognizing the infinite potential of it. One of the main research themes that has arisen in the field is to maximize the users immersion and presence. The research on audio as well as on vision therefore become significant, which is due to the limitations of the current audio technology being recognized.
Figure 1. Apple’s Vision Pro (left) and Meta’s Meta Quest3 (right) The current audio technology has limitations in regards to providing a proper level of immersion and presence that is needed in metaverse. It is hard to reflect various conditions and physical characteristics around the users, so it is difficult to provide the users with hyper-realistic audio. Many IT firms research and develop hyper-realistic audio and emphasize its importance in order to overcome limitations. Apple recently released Vision Pro, which is a head mounted display (HMD) device for spatial computing where the concept is similar to metaverse’s concept. Apple also announced the support for audio ray tracing, which is a new audio solution of Apple products. Meta also launched Meta Quest3 as an HMD device for mixed reality, which emphasizes the hyper-realistic audio of the product [1, 2]. As such, the visual experience as well as the audio experience are important for the success of metaverse. It is necessary to make innovation of sound technology in order to represent all physical characteristics of the real world and interact in a digital environment. Highlighting hyper-realistic audio technology of recent IT devices shows a reflection of the trend. The trend of audio technologies and the latest audio technology Geometric Acoustic (GA) based sound tracing are explored in this article, and the sound tracing hardware for low-power/high-performance, which was developed by our research team, is introduced. 2. The trend of audio technologies Audio technologies are presently divided into three types, which include multi-channel audio, the head-related transfer function (HRTF), and sound rendering.
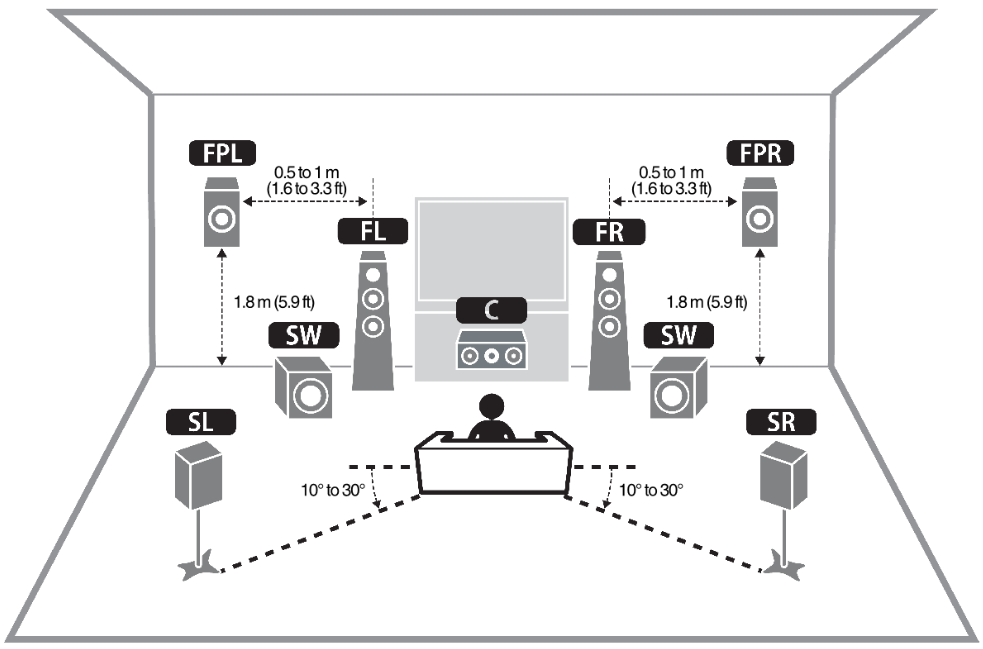
Figure 2. An example of multi-channel audio, which is on the front left (FL), front right (FR), center (C), surround left (SL), surround right (SR), front presence L (FPL), front presence right (FPR), and subwoofer (SW) * 2 [3] Multi-channel audio generates three-dimensional sound around a listener by using a variety of speakers. A listener can experience the direction of the sound just like in the real world, which is illustrated in Figure 2, with the use of a channel, such as 5.1, 7.1, or higher. Cinemas and home theaters apply the technology in order to provide a deep immersion for the listeners. Audio companies, such as Dolby and Auro3D adopted the technology for their users. However, this technology has several limitations in the metaverse environment. First, it is required to purchase speakers that support a particular type as well as prepare an installation space for the experience of multi-channel sound. Second, it is necessary to readjust sound along with the change in a user’s position or direction given that a speaker’s position is fixed. HRTF is used in order to accurately represent an amplitude of sound according to the direction of sound source. The shape of human ears and heads greatly affects how a sound is heard. HRTF uses this type of a feature. It is necessary to make the table of attenuation of sound along with the direction of the sound’s source for the implementation of this feature. The table is generated in the way of measuring the attenuation value for each frequency bandwidth in diverse directions through the speaker, the human ears, and the head shaped microphone in an anechoic room.
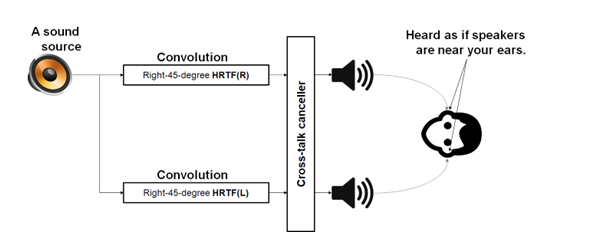
Figure 3. An example of the HRTF process Figure 3 illustrates the process of HRTF. If the direction from a sound source to ears is determined, the technology brings an attenuation value for the direction from the frequency-bandwidth and the attenuation table. It generates the final audio by applying the convolution operation to the sound source data and the attenuation value. HTRF has the attenuation value for each frequency bandwidth according to a direction, so it can provide high-quality audio for the listeners. People have different sizes and shapes of ears and heads, so it is hard to have a consistent experience. The larger the number of sound sources, the more complex the calculation becomes, and the application performance becomes worse. In addition, HRTF is a direction-specific technology that fails to reflect the effects of real physical sound. Sound rendering generates realistic sound by calculating physical sound effects around the listeners after passing the following steps, which include the sound source synthesis step to make a sound source, the sound wave propagation step to model a sound waveform, and the sound generation step in order to create a final audio signal. In other words, the technology takes into account all the interactions with the listeners, sound sources, and surroundings, which include materials, shielding, and room size, in order to generate realistic physical sound. The main step from these steps is the sound wave propagation step in order to model sound waveforms and reflect physical conditions around the listeners. Sound wave propagation is generally divided into the wave based type and the geometric acoustic (GA) based type. The wave based propagation technique implements an actual sound waveform with the use of the wave equation, which is based on the second-order partial differential equation. It is capable of generating a very realistic sound, but it requires a huge computing cost. It is impossible for this reason to apply this technique to content, such as metaverse, which needs to be processed at real-time rates. The GA based propagation technique uses rays, beams, and frustums as opposed to directly modeling sound waveforms in order to find the valid paths of the sound sources, listeners, and geometry information scene. These paths contribute to creating multiple parameters in order to generate a sound. For example, parameters, such as sound direction, sound speed, sound delay, shielding, and attenuation for frequency bandwidth are compressed and saved in the form of an impulse response (IR). The information is used when an output sound for an end-point device, such as a speaker or earphone is finally generated. The GA based technique has more relative approximation than the wave based technique, but it provides a better performance. It is therefore good for real-time applications, such as metaverse. Our research team has researched the GA based sound propagation technique using ray tracing that is called sound tracing, which is sound plus ray tracing, for a long time. Sound wave propagation is described as sound tracing in this paper. 3. Ray based sound tracing
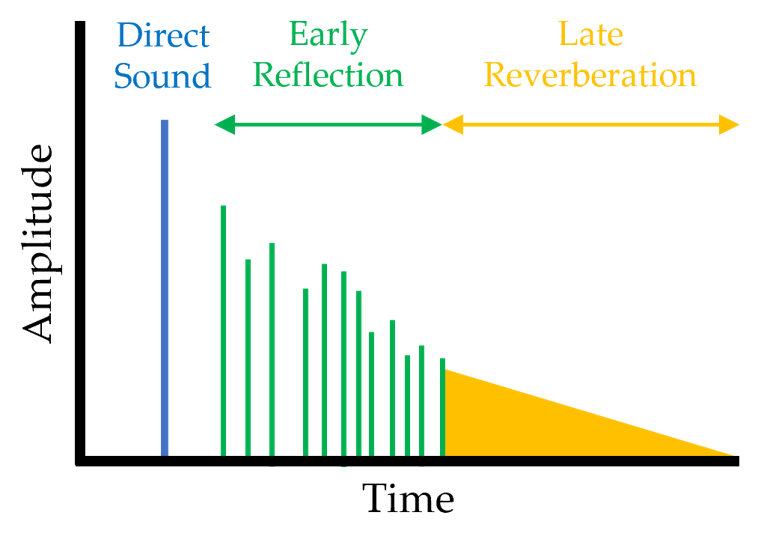
Figure 4. Amplitude of various sound effects over time, which include direct sound, ER, and LR Sound tracing can generate various sound effects with the use of rays. Figure 4 illustrates the amplitude characteristics of the sound effects, which include direct sound, early reflection (ER), and late reverberation (LR), over time. Direct sound is a directly arriving sound from a sound source to a listener. It makes a high contribution according to the direction and size of the sound source and the listener, and it has a relatively large amplitude as opposed to other sound effects. ER is the reflected sounds, which are echoes, that are heard after the direct sound arrives. ER is generally defined as the reflected sounds that meet the delay between direct sound and 60 ms. ER has a relatively small amplitude, which is due to the reflection of the objects, but it can reinforce the amplitude of direct sound and make a sound clearer. LR as reverberant sounds, which are secondary reflected sounds, means the reflected sounds are heard after ER. LR in reality is the reverberant sounds heard in concert halls. It makes a sound richer, which lets the listeners somewhat recognize the size, material, and reflectivity of their nearby space. Realistic sounds can be created when a variety of sounds effects are generated, which can be implemented with ray based sound tracing. The method is very similar to ray tracing. Ray tracing calculates the color of the light that is reflected to our eyes after the light, which is scattered in multiple directions, interact with diverse objects. Sound tracing also tries to find the sound that is heard by our ears after the rays, which are sounds, shot by a sound source are spread in multiple directions and interact with their surroundings.
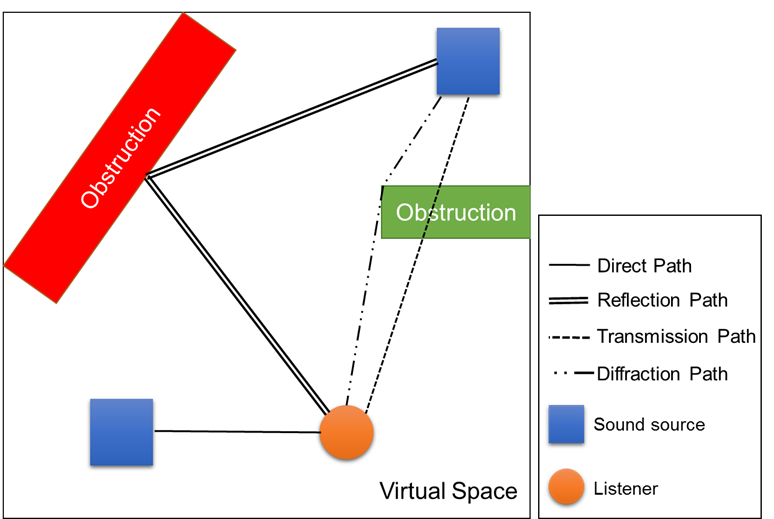
Figure 5. Types of sound tracing paths
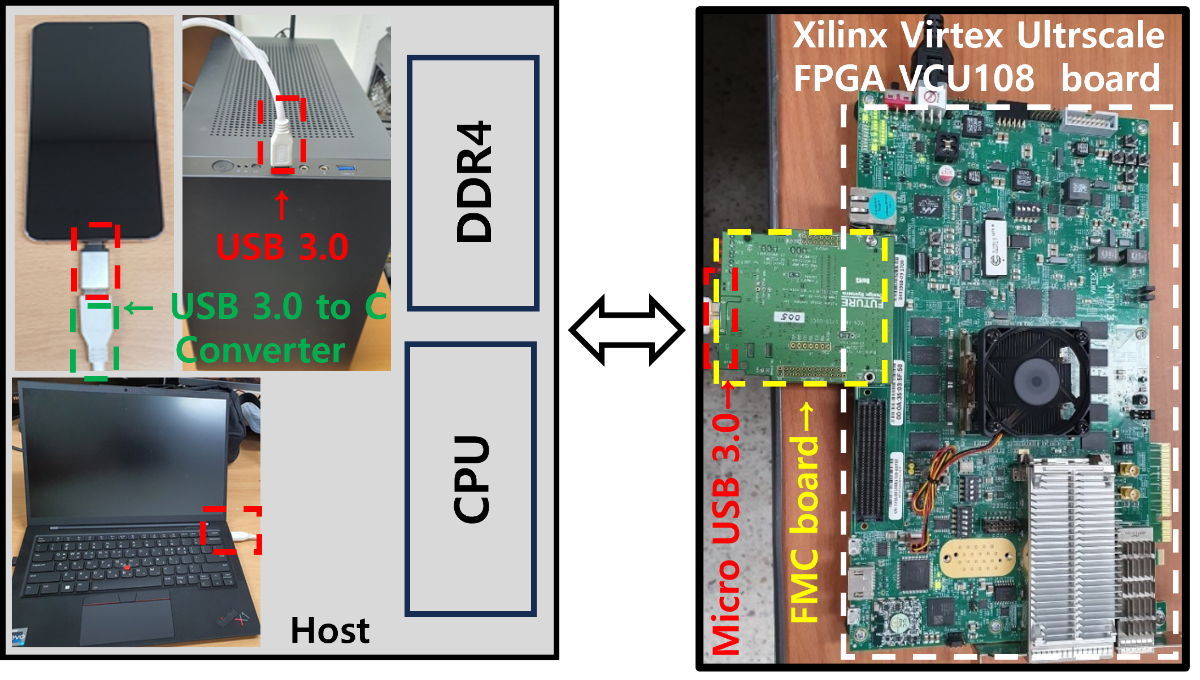
Figure 6. Mobile demonstration of sound tracing SW The procedure of sound tracing is provided next. This technique involves first shooting rays in the positions of multiple sound sources, and it then shoots a ray in the position of the listeners. Each shot ray searches for their hit primitive, which is in a triangle, and it generates reflection, transmission, and diffraction rays for the hit primitive. Each process for the rays is called generation, search, and collision inspection. These processes are recursively executed, which create the IR of the sound tracing path and the IR of the reverberation. The ray shot by a sound source or a listener can meet the listener or a sound source. The meeting path is called the sound tracing path. It means the valid path where the sound departing from the position of a sound source or a listener arrives at the listener or at the sound source via reflection, transmission, absorption, and diffraction, which are shown in Figure 5 and Figure 6. The IRs are calculated based on these sound tracing paths. Sound tracing is a model that is used in order to generate reverberation by using Eyring model [4]. It is used to calculate the intensity of a sound source and the length of the reverberation. There are essential parameters in regards to using the Eyring model, such as the width and volume of a space and the average absorption factor of the surface. The primitives shot and hit by the sound sources and listeners are used in order to calculate these parameters. The calculated parameter values are compressed and saved in a form of IRs. The final audio is generated with the IRs of sound tracing paths and the IRs of reverberation, which goes out through a speaker or headset. Sound tracing is an audio technology that is suitable for a hyper-realistic metaverse, but it has several disadvantages. First, it needs a lot of computing resources. If other critical processes, such as graphic processing are influenced due to these resources, it is possible to cause an overall problem with an application. Second, it consumes too much power. High power consumption causes throttling¹ in a mobile environment, which leads to a poor performance. Lastly, if the number of sound sources is large, sound tracing has more computing complexity, so it fails to reach the performance for real-time processing, such as FPS or 60 FPS. Our research team designed and implemented the hardware for sound tracing in order to overcome these weaknesses. We accomplished low-power/high-performance this way as well as supported a fully dynamic scene² in order to provide a stable high-quality audio experience in a metaverse setting. ¹Throttling: A technique of lowering a clock or voltage by force or powering off in order to preventing overheat of the CPU or GPU. ²Dynamic scene: A setting of objects changing over time or reacting to a user’s interaction. 4. Sound tracing hardware of our research team The sound tracing hardware is based on ray tracing hardware, so it has a very high level of technological complexity. No sound tracing hardware has been developed in the world thus far. Our research team ended up designing and implementing the sound tracing hardware with our 20 years of R&D know-how about ray tracing hardware [6, 7]. Figure 7 illustrates the Xilinx board with sound tracing IP³, the host, which is a PC or mobile device, and the FMC board for the communication between the Xilinx board and the host. The sound tracing hardware first receives the geometry data, sound source data, and acceleration structure⁴ information from the host through USB3.0. It receives a hardware start signal, and the sound tracing unit that takes charge of sound tracing starts to run.
Figure 7. The sound tracing hardware consists of Xilinx Virtex Ultrascale with sound tracing IP and the FMC board in order to communicate with the host, which transmits the host data through USB 3.0.
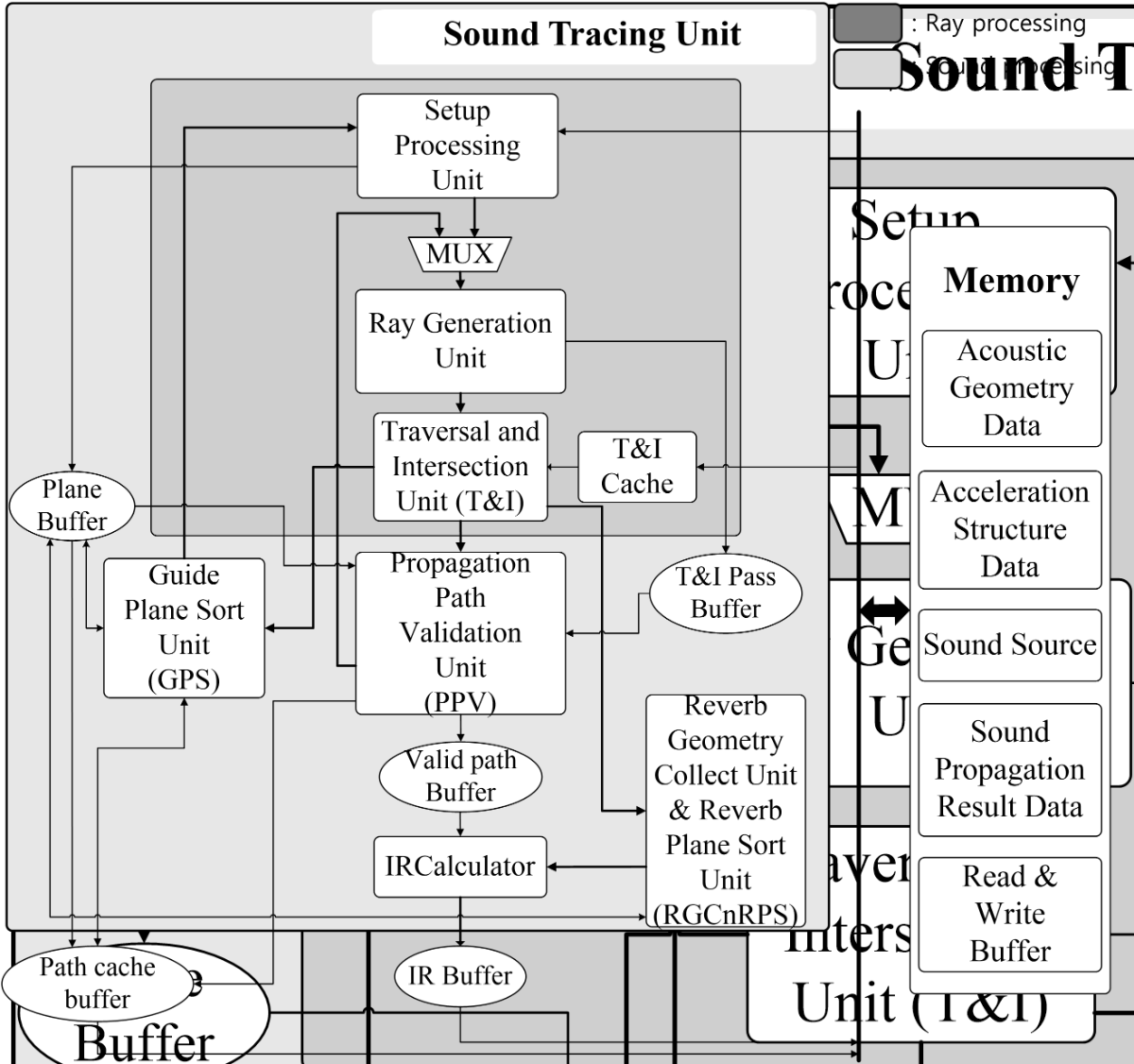
Figure 8. The entire architecture of the sound tracing unit designed by our research team Figure 8 illustrates the entire architecture of the sound tracing unit that was designed by our research team. It consists of ray processing and sound processing. Ray processing incorporates the units for ray tracing, which plays roles for the generation, search, and cross-testing of rays. Sound processing includes the units to find valid paths for the sound generation. It checks types the reflection and the diffraction of paths that the primitives found by ray processing can generate, verifies whether these paths are valid, and calculates the IRs for the valid paths.
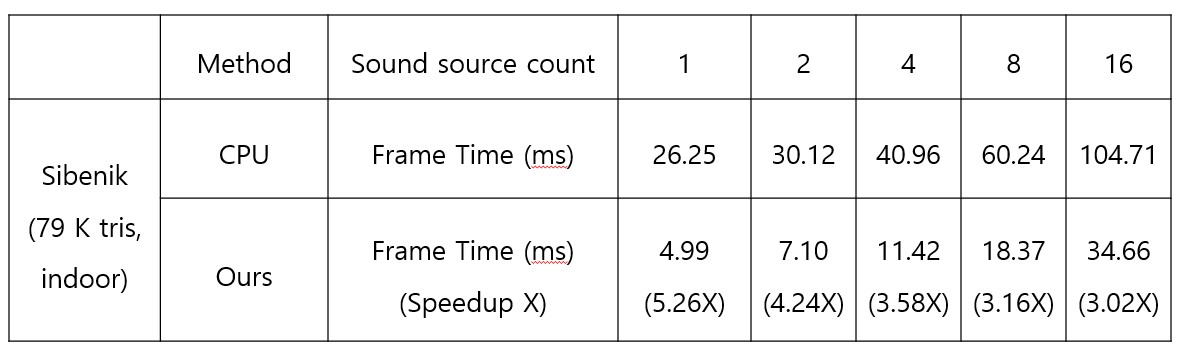
Table 1. Performance comparison between CPU-typed hardware and the sound tracing hardware according to the different counts of the sound sources Our research team compared our system with the CPU (i9-10850k 3.6GHz) acceleration typed sound tracing in the Sibenik (79,000 triangles and indoor) scene that is most used in the graphics field in order to measure the performance of the sound tracing FPGA(140MHz). Our team measured the average frame time, which is the processing speed, of the sound tracing in the comparison test by increasing the sound source count. As a result, the sound tracing FPGA’s average processing speed was 3.85 times faster than the CPU acceleration-typed sound tracing. Our research team applied the performance, power, and area (PPA) index, which is widely used in order to evaluate the performance, power, and area of ASIC in the semiconductor design field for the performance measurement of the sound tracing ASIC⁵. We used an 8nm design process and a design compiler tool for the index based measurement. The hardware for the PPA of the sound tracing ASIC had a 900MHz performance, 50mW of power, and was 0.31mm² in size. The performance of ASIC increased about 6.42 times more than the FPGA, and the power of ASIC was considerably different from the power of i9-10850k (125W). The size of ASIC is very small given that the size of a recent mobile AP is more than 100 mm² [5]. These results prove that the performance, power consumption, and size of the sound tracing hardware that was developed by our team are excellent, and the developed sound tracing is capable of implementing real-time 3D audio for a hyper-realistic metaverse. ³ Intellectual property (IP): Intellectual property is related to the circuit design for a particular function. ⁴ Acceleration structure (AS): A structure that is used in order to efficiently split a 3D space, which is saved in a tree type, and it efficiently finds the cross points of rays and objects. ⁵ Application-specific integrated circuit (ASIC): An integrated circuit that is customized for a particular application or function, such as a semiconductor. 5. Conclusion There has been a considerable amount of research and development effort in regards to maximizing user immersion, because more attention is been paid to metaverse globally. Audio in particular plays a critical role in regards to the user experience in a metaverse setting. Sound rendering emerges as a key technology in order to increase the immersion. Conventional audio processing techniques have limitations in regards to improving, whereas sound rendering provides a high level of immersion and the presence of audio experience. Sound rendering unfortunately requires high operation costs, so there is difficulty with real-time processing. Our research team, which significant development experience with ray tracing hardware, designed and implemented the sound tracing hardware with a high performance in order to solve the problem. This hardware’s processing speed is on average 3.85 times faster than the CPU-typed hardware. The developed hardware is excellent in terms of its performance, power consumption, and size. The performance of sound tracing ASIC is in particular about 6.42 times higher than that the performance of FPGA, which is good enough to provide real-time audio in a hyper-realistic metaverse setting. The sound tracing hardware that was developed by our research team will lay the foundation in regards to providing a solution to an application for high-performance audio processing, such as a hyper-realistic metaverse given these results. It is possible to establish a more realistic metaverse setting with excellent immersion via the efforts and innovation of our research team. References [1] https://www.wepc.com/tips/apple-audio-ray-tracing-explained/ [2] https://about.fb.com/news/2023/09/meet-meta-quest-3-mixed-reality-headset/ [3] https://manual.yamaha.com/av/18/rxv685/en-US/448935819.html [4] Carl F Eyring. 1930. Reverberation time in “dead” rooms. The Journal of the Acoustical Society of America 1, 2A (1930), 217–241. [5] https://www.anandtech.com/show/16983/the-apple-a15-soc-performance- review-faster-more-efficient/3 [6] Eunjae Kim, Sukwon Choi, Jiyoung Kim, Jae-ho Nah, Woonam Jung, Tae-hyeong Lee, Yeon-kug Moon, and Woo-chan Park, "An Architecture and Implementation of Real-Time Sound Propagation Hardware for Mobile Devices," SIGGRAPH ASIA, Accepted to appear. [7] Eunjae Kim, Sukwon Choi, Cheong Ghil Kim, and Woo-Chan Park, "Multi-Threaded Sound Propagation Algorithm to Improve Performance on Mobile Devices," Sensors, Vol. 23, No. 2, p. 973. Jan 2023. |
|
| Next | Breakdown of the Newton-Einstein Standard Gravity in Wide Binary Stars: A Revolution in Astrophysics and Cosmology |
| Previous | Direct evidence for modified gravity at low acceleration is reinforced by a new study of wide binary stars |